
Successful data science projects are heavily dependent on the data that are used. Ensuring that data is collected, appropriately transformed, and made accessible requires data engineering skills. Without an architecture that can structure and format growing and changing datasets, there are unable to make accurate predictions. This is where data engineering comes into play. Data engineers make complex datasets usable, thus allowing data scientists, analysts, and other consumers of data to work their magic.
What is Data Engineering?
Data engineering is about collecting, storing, and processing data. It involves everything from planning to keep your data for long-term use to finding ways to ensure your servers can handle all the new information you’re collecting.
The amount of data an engineer works with varies from the project. The more complicated project, the more complex the analytics architecture, and the more data the engineer will be responsible for. In this case, there are usually many different types of operations management software, all containing databases with varied information. Besides, data can be stored as separate files or pulled from external sources — such as IoT devices — in real-time. Having data in different formats prevents the organization from seeing a clear picture of its business state and running analytics. And data engineering addresses this problem step by step.
Data engineers work in conjunction with data science teams, improving data transparency. It helps businesses understand their company’s operations by turning raw numbers into meaningful information. The process of data engineering helps to convert haphazard, meaningless data into organized information, that gives an understanding of the current state of the business and makes data-informed decisions.
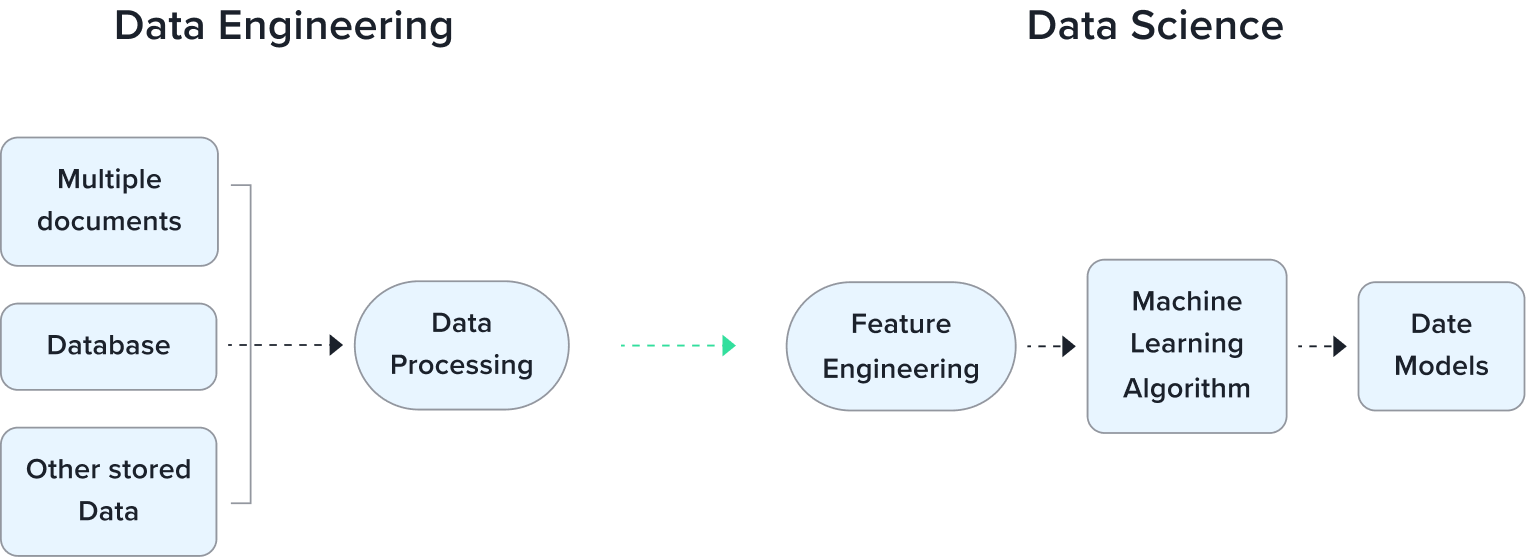
How does it Work?
The data engineering process is a sequence of tasks that turn a large amount of raw data into a practical product meeting the needs of analysts, data scientists, machine learning engineers, and others. The data processing process includes the following points:

Data Lake
When the data is raw, they are located in a data lake. A data lake is a centralized repository that allows for storing all structured and unstructured data at any scale. It stores relational data from line of business applications, and non-relational data from mobile apps, IoT devices, and social media. The structure of the data or schema is not defined when data is captured. Data Lakes are an ideal workload for deploying in the cloud because the cloud provides performance, scalability, reliability, availability, and massive economies of scale.
Pipeline
The data pipeline can automate the engineering process. A data pipeline receives data, standardize and moves it for storage and further handling. Constructing and maintaining data pipelines is the core responsibility of data engineers. Among other things, they write scripts to automate repetitive tasks. Pipelines are used for:
- data migration between systems or environments;
- data wrangling or converting raw data into a usable format;
- data integration from various systems and IoT devices;
- copying tables from one database to another.
Besides a pipeline, a data warehouse must be built to support and facilitate data science activities.
ETL pipeline
ETL pipeline is the most common architecture that has been here for decades. It automates the following processes:
Extract — retrieving raw data from numerous sources — databases, APIs, files, etc.
Transform — standardizing data to meet the format requirements.
Load — saving data to a new destination (typically a data warehouse).
When the data is transformed and loaded into a centralized repository, they are ready for further analysis and business intelligence operations, generating reports, creating visualizations, etc.
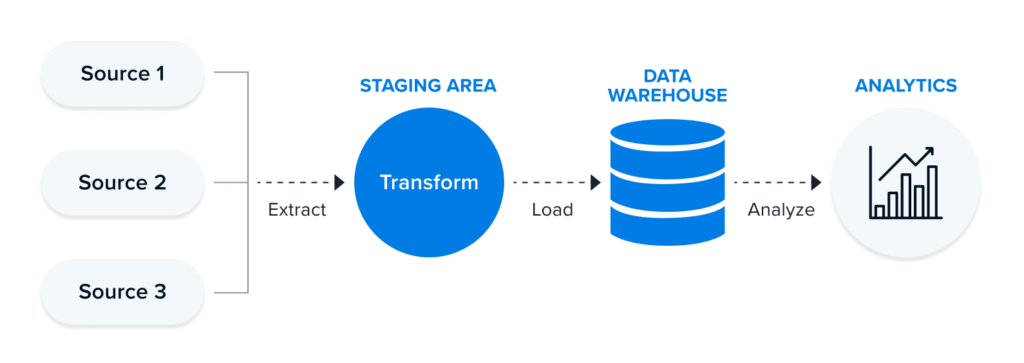
Data Warehouse
A data warehouse is a central repository storing data in queryable forms. Without this, data scientists would have to pull data straight from the production database. This may cause different results to the same question or delays and even outages. Serving as an enterprise’s single source of truth, the data warehouse simplifies the organization’s reporting and analysis, decision-making, and metrics forecasting.
Why is it Important
- The amount of data continues to grow exponentially each year.
- Processing large amounts of data without overloading systems allows for scalability.
- Robustly built and optimized data architecture allows to prevent errors from occurring when working on large amounts of data.
- Companies with good data engineering practices can use their data to make better decisions and get a leg up on their competitors.
- Data engineering helps companies organize themselves more efficiently: it can handle as much volume as possible while still being cost-effective.
Data Engineering and Data Science
Data engineers and data scientists are two different types of professionals that work together to bring a company’s goals to life.
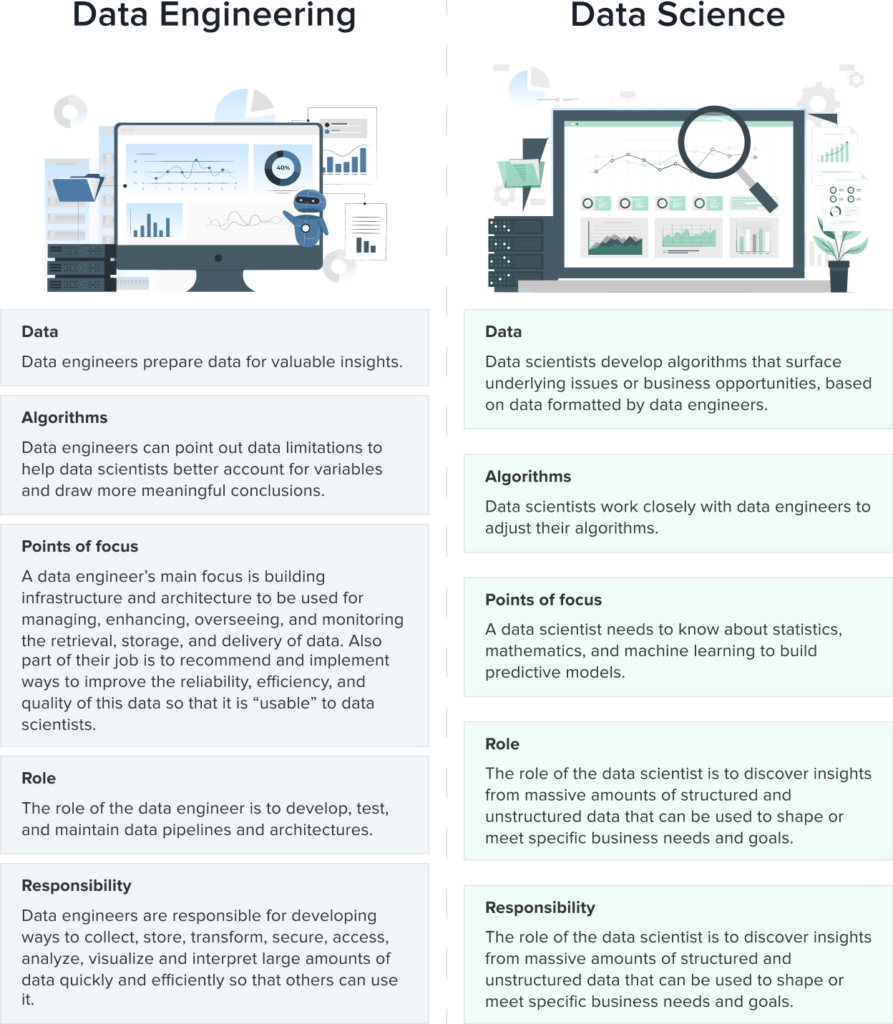
To sum up, data scientists tackle new, big-picture problems, while data engineers put the pieces in place to make that possible.
Conclusion
Data engineering is a crucial part of successful data science and analytics implementation. Without the right software and structure, data scientists would yield different results from the same research question. As a result – end users could experience outages, or pipelines may malfunction causing data scientists to spend hours on repetitive, manual deep dives. Companies need a cloud-based ETL/ELT solution with ample data storage and self-service capabilities.
As the volume of data continues to significantly increase, it comes as no surprise that data engineering is only predicted to rise in significance for businesses small and large. After all, data engineers have the vital role of managing, enhancing, overseeing, and monitoring the retrieval, storage, and delivery of data throughout the business. In doing so, they make vital data more usable for a number of key stakeholders. With data engineering, data scientists have the power to offer invaluable insights that could disrupt entire industries.
Nowadays businesses are discovering more ways to use data to their advantage. Data can help them to understand the current state of their business, predict the future, learn more about their customers, reduce risks, and create new products. Data engineering is the key player in all of these scenarios.
Contact Amazinum team to get professional advice and implement new technologies for the development of your business.



