2023 can be called the year of Large Language Models (LLM). They won their place in almost every field of business and became a new trend. However, this year – 2024 will surprise you much more because it can become the year of Multimodal Artificial Intelligence. It increasingly relies on human senses than its predecessors and can process multiple inputs such as text, voice, video, and thermal data. So this year, Multimodal Artificial Intelligence models such as GPT-4V, Google Gemini, and Meta ImageBind will be revealed even more.
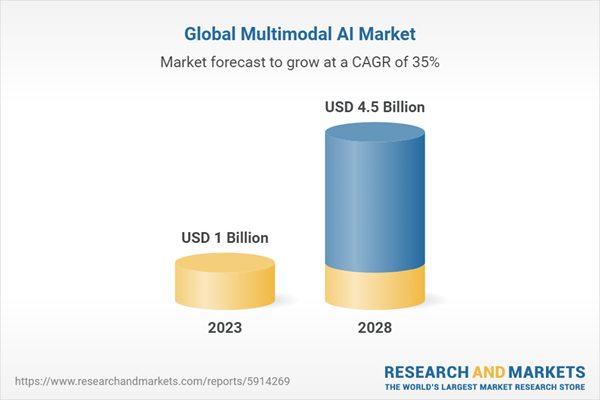
Source: Link
What is Multimodal Artificial Intelligence ?
Developments and breakthroughs in generative Artificial Intelligence are making ever greater strides toward its ability to perform a wide range of cognitive tasks (AGI). Despite this, it still cannot think like a human. The human brain relies on 5 senses, which serve as collectors of information from the surrounding environment. After that, the information is processed and stored in our brains.
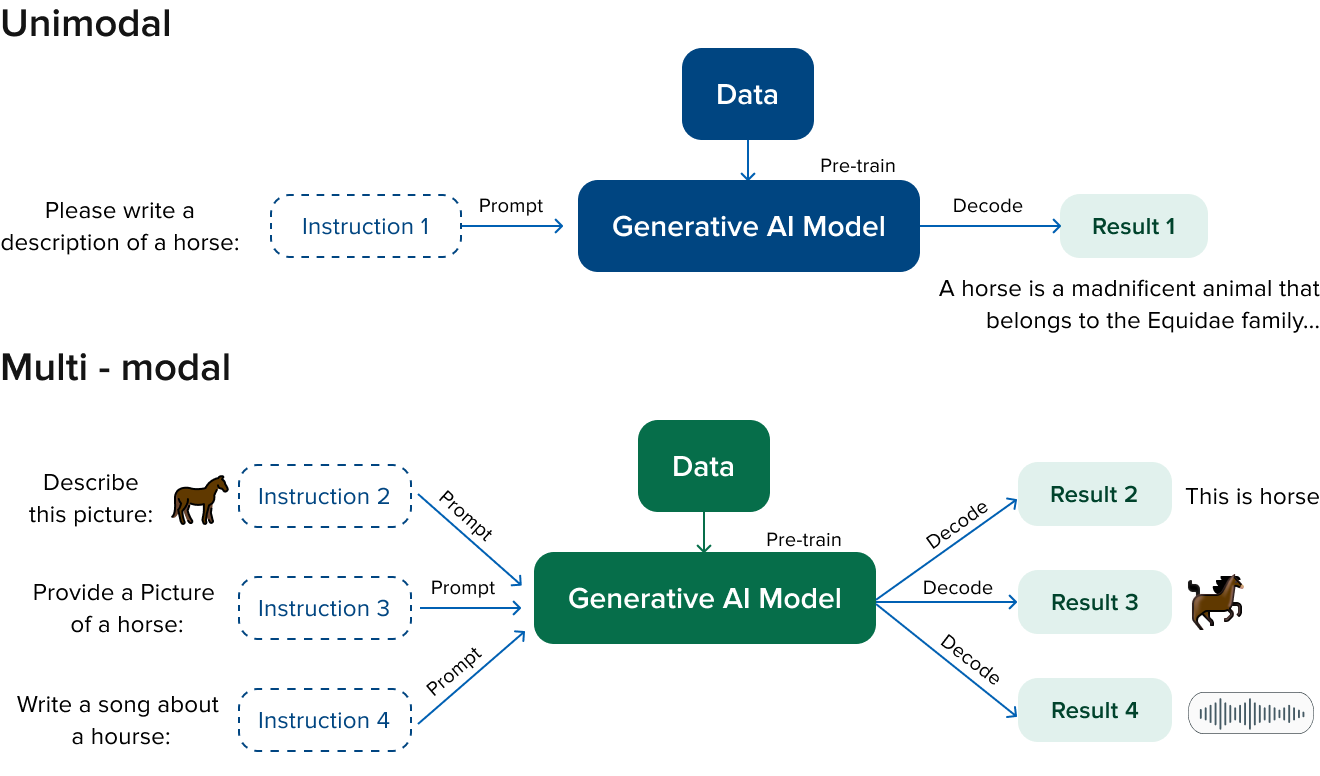
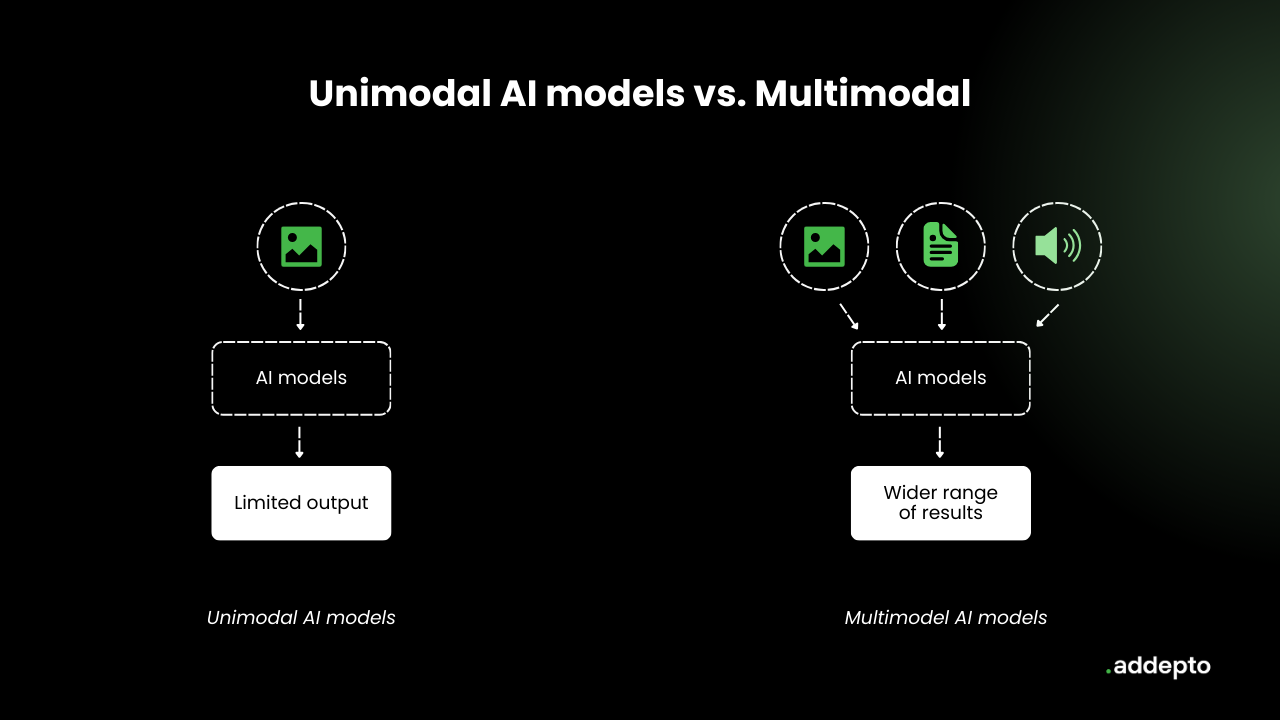
Generative models such as ChatGPT can only accept and generate one type of data. That is, they are unimodal. They were mostly used to provide text prompts and generate a text response.
Multimodal learning aims to increase the ability of machines to learn by presenting them with sensory types of data, i.e. images, videos or audio recordings. With this model, the correlation between textual descriptions and associated images, audio or video is studied. Currently, multimodal learning opens many perspectives for the modern technological world. Their ability to generate multiple types of outputs allows us to see new opportunities and developments.
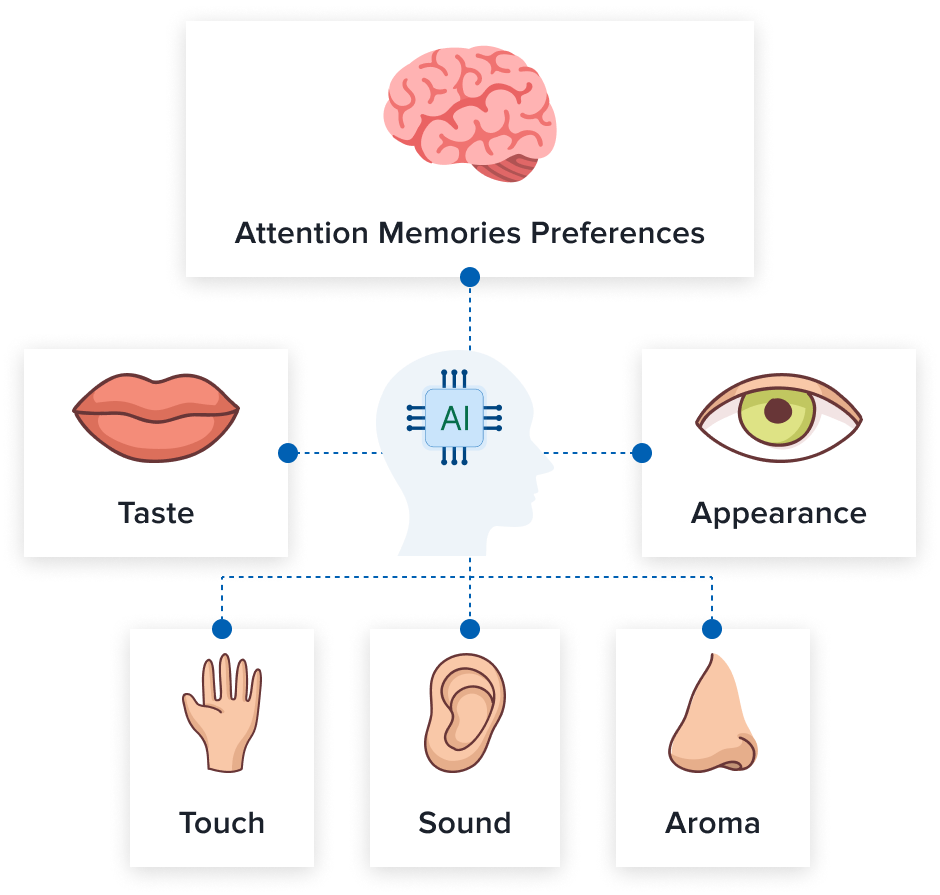
Difference between Multimodal Artificial Intelligence and Unimodal





How Does Multimodal Artificial Intelligence Work?
Key Components of Multimodal AI Models

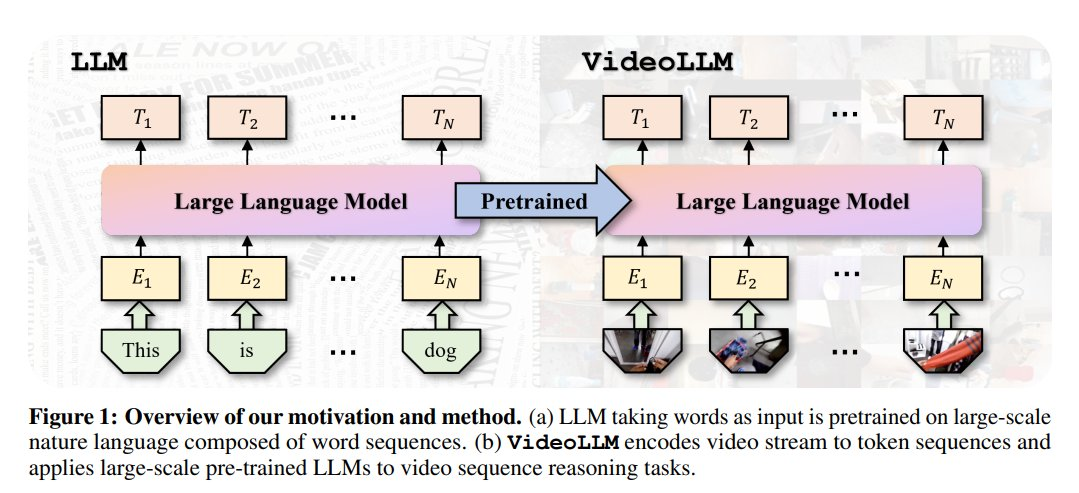
The development of transforms opened new possibilities for multimodal AI. The structure of transformers made it easier to experiment with the models’ architecture. Transformer consists of two parts – an encoder (transforms the input into a feature vector – a meaningful representation of the input information) and a decoder (generates information based on the encoder’s output). At first, transformers were used in language processing and text generation (LLMs) and later on were trained for image captioning, visual question answering, visual instruction, and other multimodal tasks. This leads to the possibility of creating a Large Vision-Language Models that have visual and textual encoders, can combine the representation of these two modalities, and can generate language responses (such as GPT-4V or LLaVA).
Another common approach is a combination of the Large Language Model with other capable models where LLM handles reasoning processes and other models (such as Latent Diffusion Models or TextToSpeech Models) generate new modalities. Such ansamble of models is more suitable to handle differences in architectures (transformers are great in handling language processing but diffusers are better for image generation) and allow higher modularity.
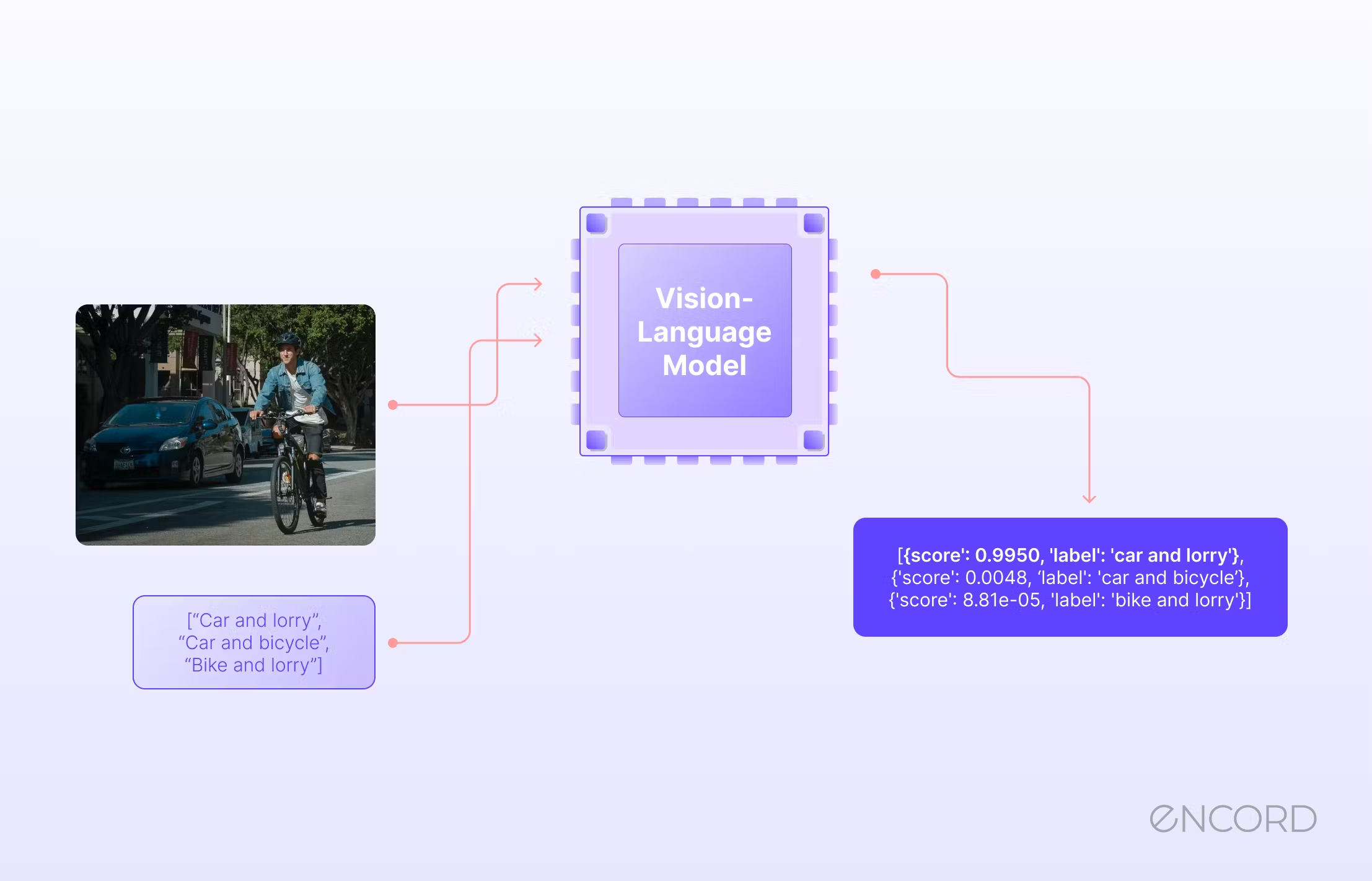
How Do Various Input Types Affect the Operation of Multimodal Models?
The multimodal AI architecture functions as follows for various input kinds. To facilitate comprehension, we have incorporated actual instances as well.
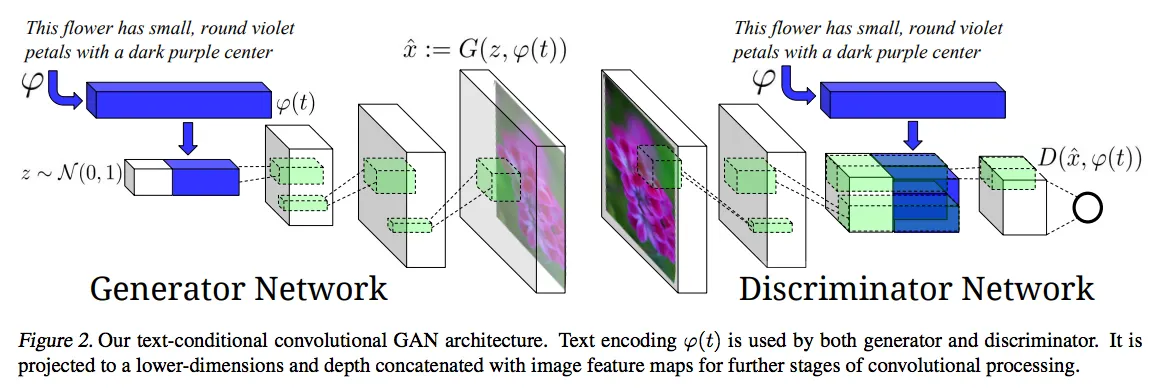
Text-to-image Generation and Image Description Generation
Some of the most revolutionary models of text-to-image generation and image description generation are GLIDE, CLIP, and DALL-E. Their specialty is the ability to create images from text and help describe images.
OpenAI CLIP has specific text and image encoders. They predict specific images in a dataset by training on massive datasets. In addition, if the model is subject to both an image and a corresponding textual description, it can use multimodal neurons. All this together represents a merged multimodal system.
DALL-E has about 13 billion parameters. It generates an image according to the input request. CLIP is used to rank images. This allows for accurate and detailed images.
CLIP also ranks images for GLIDE. However, it uses a diffusion model, which allows it to obtain accurate and realistic results.
Visual Question Answering
This query assumes correct answers to the questions based on the presented image. Microsoft Research is at the forefront of this, offering creative and innovative approaches to visual responses.
METER for example uses sub-architectures for rendering encoders, decoding modules, text encoders, and multimodal fusion modules.
The Unified Vision-Language Pretrained Model (VLMo) suggests the use of different encoders. Among them are dual encoders, fusion encoders, and a network of modular transformers. The flexibility of the model is primarily due to its levels of self-control and blocks with experts in specific modalities.
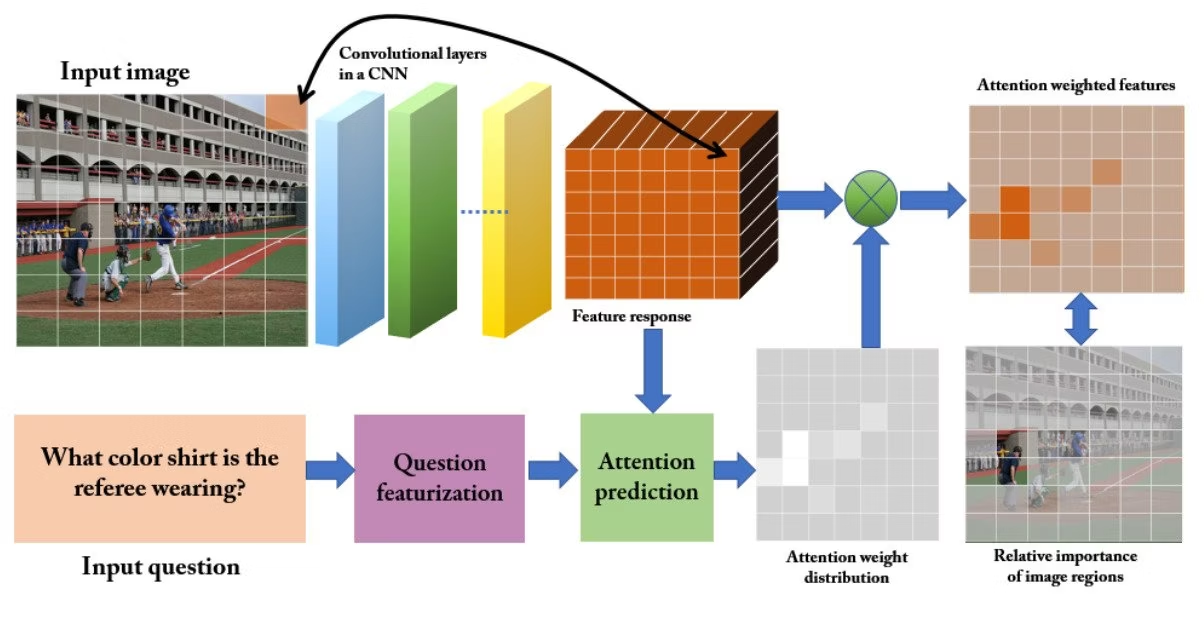
Image-to-text Search And Text-to-Image
Web search is also not aloof from the multimodal revolution. Datasets such as WebQA, which was created by researchers and developers at Carnegie Mellon University and Microsoft, allow models to identify sources of text and images with exceptional accuracy. This helps to answer the request correctly. However, the model will still need multiple sources to provide accurate predictions.
Google ALIGN (Large-scale Image and Noisy-Text Embedding model) uses alt text data from images on the Internet to train text (BERT-Large) and clear visual coders (EfficientNet-L2).
After that, the results of the encoders are combined using a multimodal architecture. This creates powerful models with multimodal representation. They can provide web searches in several modalities. At the same time, no additional configuration is required.
Video-Language Modeling
To bring Artificial Intelligence closer to natural, multimodal models designed for video were created.
Microsoft’s Florence-VL project uses a combination of transformer models and convolutional neural networks (CNN) in its ClipBERT project. They work with a thin selection on cards.
SwinBERT and VIOLET, iterations of ClipBERT, use Sparse Attention and Visual-token Modeling to perform better in answering video questions/subtitles/searches.
ClipBERT, SwinBERT, and VIOLET work similarly to them. Their ability to acquire video data from multiple modalities relies on a transformer architecture along with parallel learning modules. That is why they can integrate responses into a single multimodal representation.
Multimodal AI Models
Currently, many models contribute to the study of multimodality in Artificial Intelligence. Here are a few of them:
Mistral
Mistral is a large LLM language model. It has an open-source code and can efficiently and quickly process very long text sequences. Mistral’s architecture allows you to have a smaller number of parameters and get conclusions faster. This makes it convenient for applications that require large text sequences.
Efficient processing and generation of text in different languages is enabled by the architecture of the model, which is based on a mixture of experts (MoE), natural language processing (NLP) and natural language understanding (NLU).
LLaVA
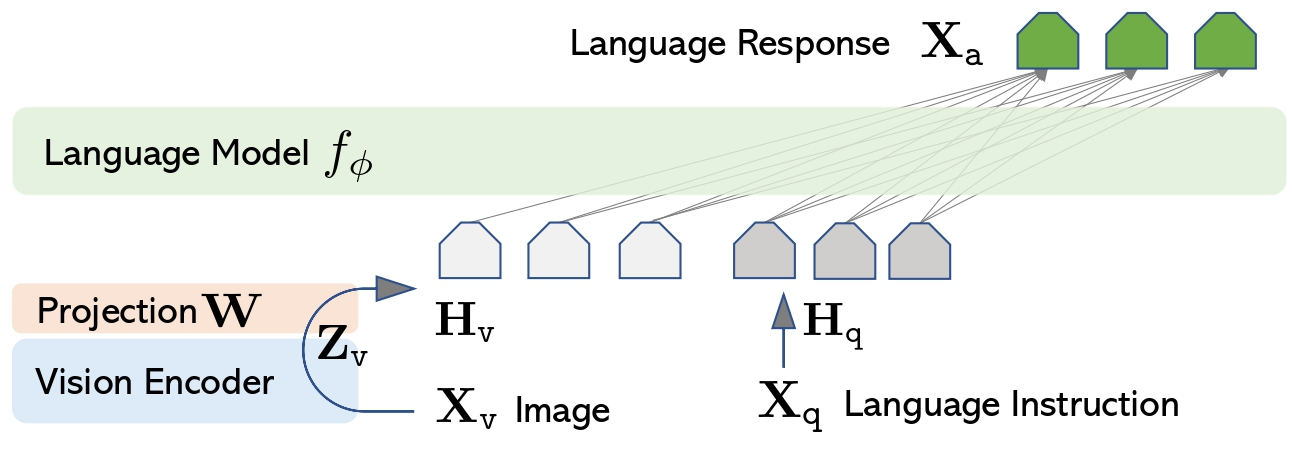
LLaVA combines Large Language and Vision Assistant. It is a multimodal model that aims to improve the integration of visual and textual data. To provide visual language understanding, LLaVA leverages a visual encoder with a large Vicuna language model.
LLaVA can create content in various forms such as text, images, and audio. Thanks to this, it can provide the most accurate results in various tasks such as Science QA.
ImageBind
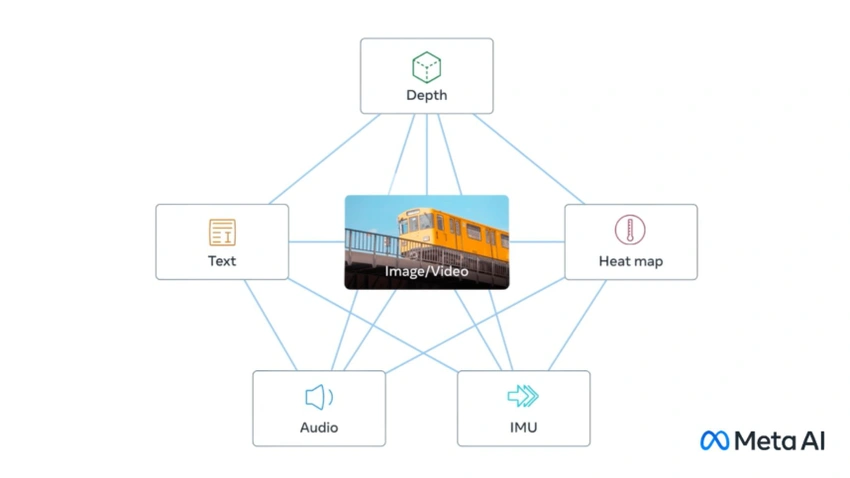
ImageBind was created by Meta as an advanced model of artificial intelligence. Its revolutionary nature lies in the perception and combination of data from different modalities. This creates a unified representation space. In it, the data of various modalities are transformed into a format understandable for the model. The model has the power to process data from six different modalities, such as images, text, audio, depth images, thermal images, and inertial measurement units (IMUs). ImageBind can better analyze and interpret complex datasets.
Gen 2
Gen-2, created by Runway Research, builds on the basic functions of its predecessor, Gen 1. To study large video data sets and create high-quality video outputs, it uses stable diffusion techniques. Gen-2 synthesizes video from text or images, creating realistic and coherent video.

CLIP
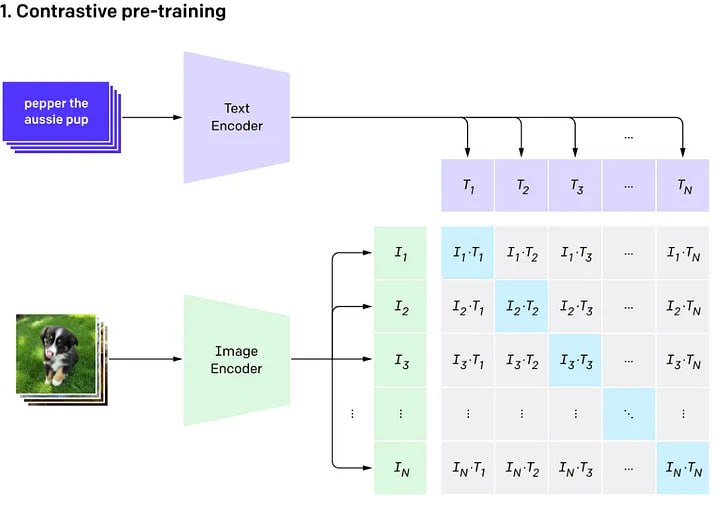
OpenAI has developed a CLIP (Contrastive Language-Image Pre-training) model for understanding image classification using natural language descriptions. The model does not require large datasets with labels and thus departs from traditional approaches. CLIP does not need training data for a specific task, it can simply summarize them.
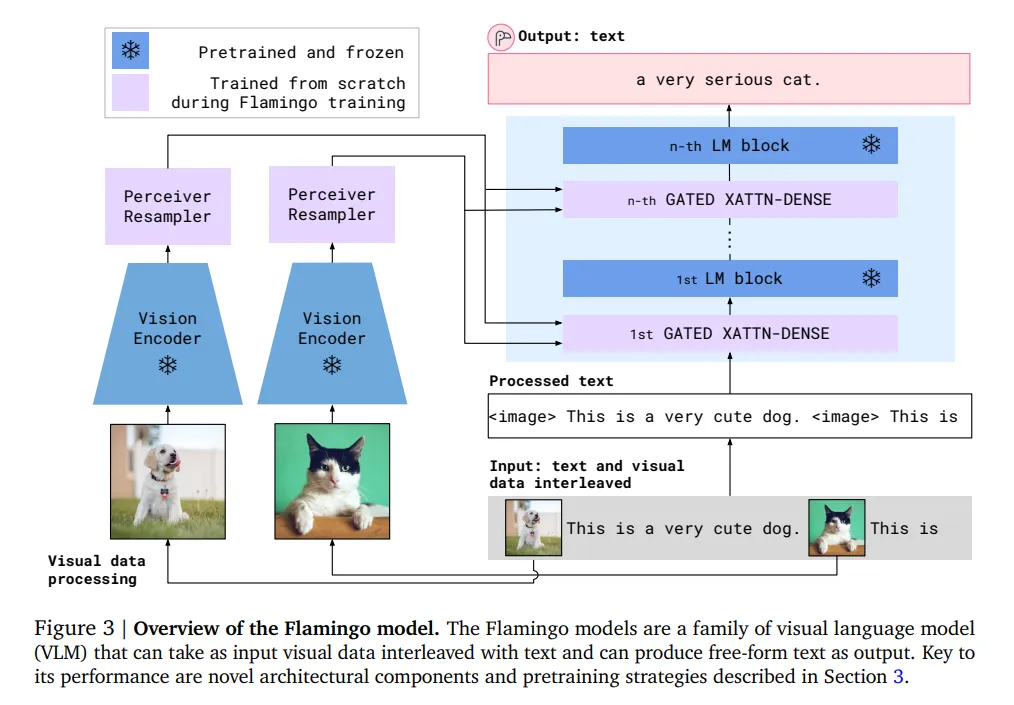
Flamingo
Flamingo, developed by DeepMind, is a Visual Language Model (VLM). Its main purpose is to perform tasks that require understanding of visual and textual information.
Flamingo can process and generate responses based on combinations of text and visual input. This is due to its ability to integrate the capabilities of vision and language models. Because of this, Flamingo successfully handles various tasks such as answering questions about images, creating textual descriptions of visual content, and participating in dialogues that require an understanding of visual context.
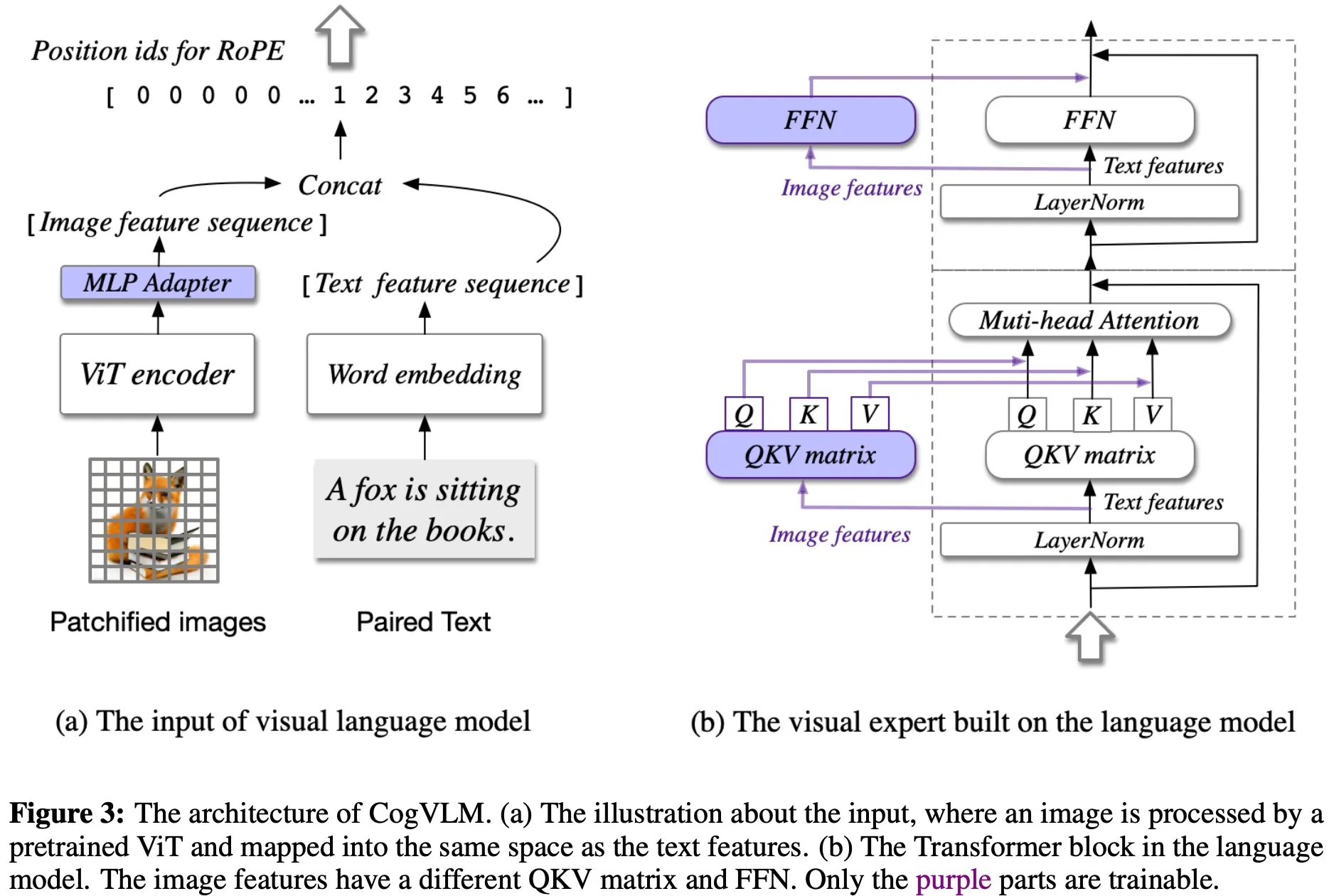
CogVLM
CogVLM (Cognitive Visual Language Model) aims to improve the integration of visual and text data. It is an open-source model that bridges the gap between vision and language understanding. The model does not harm the performance of NLP tasks because it does not use the shallow alignment method, unlike traditional models. CogVLM demonstrates efficiency and performance in a variety of tasks and numerous classic cross-modal tests.
Advantages of Using Multimodal Models of Artificial Intelligence
Advantages of MultiModal AI

Contextual Understanding
By analyzing words, surrounding concepts, or sentences, multimodal systems can understand them. This is especially difficult when processing natural language. After all, it makes it possible to understand the concept and essence of the sentence to give an appropriate answer. A combination of NLP and multimodal Artificial Intelligence can understand the context by combining linguistic and visual information.
Thanks to the ability of Multimodal AI to consider both textual and visual cues, they are a convenient method of interpreting and combining information. In addition, they can understand the temporal relationship between sounds, events, and dialogues in a video.
Much Higher Accuracy
Combining multiple modalities, such as text, image, and video, can provide greater accuracy. With a comprehensive and detailed understanding of the input data, multimodal systems can achieve better performance and provide more accurate predictions.
Modalities provide more descriptive and accurate signatures, and improve natural language processing operations or face recognition to obtain more accurate information about the speaker’s emotional state. They can fill in missing gaps or correct errors using information from multiple modalities.
Natural Interaction
Facilitate interactions between users and machines. This is due to the ability of multimodal models to combine multiple input modes, including text, speech, and visual cues. In this way, they can more fully understand the needs and intentions of the user.
Humans can easily interact with machines in conversation. A combination of multimodal systems and NLP can interpret a user’s message and then combine it with information from visual cues or images. This will allow you to fully understand the meaning of the user’s sentences, his tone, and emotions. Thanks to this, your chatbot will be able to provide answers that will satisfy the user.
Improved Capabilities
Multimodal models make it possible to achieve a greater understanding of the context, because they use information from several modalities, and thereby significantly improve the overall capabilities of the artificial intelligence system. In this way, AI can be more productive, more accurate and more efficient.
Multimodal systems also bridge the gap between people and technology. They help machines to be more natural and understandable. AI can perceive and respond to combined queries. This increases customer satisfaction and allows you to use technology more effectively.
Use Cases of Multimadal AI for Business
Healthcare
To improve patient outcomes and tailor treatments, multimodal AI examines medical images, patient records, and genetic data to assist physicians. By evaluating a variety of patient data, including medical images, electronic health records, and patient symptoms, multimodal AI in healthcare can help with medical diagnosis. It can assist medical professionals in reaching more precise diagnosis and treatment conclusions.
Retail and E-commerce
To make your online shopping experience even more amazing, Multimodal AI looks through product pictures, reviews, and what you’ve previously looked at to recommend items you’d probably love.
To enhance search efficiency and recommendation systems in online retail, multimodal AI can examine product photos and descriptions. Additionally, it can help with visual search capabilities, enabling users to look for products through pictures.
Agriculture
Using satellite imagery, meteorological information, and soil data, farmers utilize multimodal AI to inspect crops. It assists them in making decisions about fertilizer and irrigation, improving crop quality, and cost savings.
Customer Assistance and Support
Multimodal AI analyzes text, voice, and image inputs to improve customer service interactions. Through chatbots or virtual assistants, it can help with sentiment analysis, understanding customer inquiries, and providing tailored responses.
Marketing and Advertising
Through the processing of text, photos, and videos from social media, online reviews, and other sources, multimodal AI is able to analyze consumer behavior. By offering insights into consumer trends, sentiments, and preferences, it can help businesses better target their marketing campaigns.
Education
By examining student performance information, multimedia materials, and learning preferences, multimodal AI can tailor educational experiences. It can provide assignment feedback, suggest personalized study materials, and modify instruction to meet the needs of each unique student.
FinTech
In the finance industry, multimodal AI can evaluate numerical data, like stock prices and transaction records, and textual data, like news articles and financial reports, to determine credit risk, make investment decisions, and identify fraud.
Supply Chain Management
By evaluating a combination of textual data (like purchase orders and inventory reports) and visual data (like CCTV footage and satellite imagery), multimodal AI can optimize supply chain operations. It can forecast demand, spot inefficiencies, and enhance inventory control procedures.
Companies That Already Use Multimodal AI
- Mercedes-Benz
Mercedes-Benz uses multimodal artificial intelligence (AI) in its MBUX (Mercedes-Benz User Experience) infotainment system, which recognizes voices and uses natural language processing to control a number of the car’s functions. - Snap Inc. (Snapchat)
For tasks like image and video processing, augmented reality (AR) effects, and content moderation, Snap Inc. uses multimodal AI in its Snapchat app. Snapchat creates interactive experiences and improves user engagement through the use of multimodal AI. - Sony
Multimodal AI is used by Sony in products such as the Aibo robot dog, which interacts with its surroundings through sensors and cameras. For functions like autofocus and image stabilization, Sony incorporates multimodal AI into its digital imaging products. - Ford
Ford incorporates multimodal AI into its cars to perform functions like voice recognition, natural language processing, and driver-assist features. The company also employs multimodal AI in its mobility services and autonomous vehicle research. - Alibaba
Alibaba uses multimodal AI for image recognition, recommendation engines, and product search on its e-commerce platforms. They optimizes operations in supply chain management and logistics through the use of multimodal AI. - McDonald’s
For tasks like speech recognition and order customization, McDonald’s uses multimodal AI in its drive-thru and kiosk ordering systems. Multimodal AI is also used by McDonald’s for marketing campaigns and customer analytics.
Conclusion
Multimodal Intelligence has already penetrated almost all areas of business. It narrows the gap between machines and humans and is already showing its effectiveness in contest answers. 2024 may be the year of multimodal Intelligence. And we will only have to watch it!



