Data Engineering For an American Clothing Company
Technologies:

About the Client
Our clients are a successful American apparel company Phillips-Van Heusen Corporation, that owns the Tommy Hilfiger, Calvin Klein, Warner’s, and True & Co. brands. PVH is one of the world’s largest lifestyle companies. It works with consumers in more than 40 countries.
Business Context
The client provided Amazinum Data Engineers with access to their GCP BigQuery database, Airflow script orchestrator, development environment, and schema of their existing data pipeline. The goal was to reduce the amount of code and optimize its performance for better performance.
Challenges Faced
A large amount of duplicate code that was run with Airflow, which negatively affected processing performance, code readability, and the ability to modify it for further work with it.
The Tasks Set For Data Engineers by the Client:
- Analyze the code and its functionality, taking into account the principles of refactoring and optimization for maximum efficiency in working with data.
- Study and analyze the mechanisms for loading data into the pipeline processing, including methods of integration with GCP BigQuery.
- Determine the number and sequence of data processing stages, taking into account streaming and batch processing, as well as the principles of parallelism and distribution of computations.
- Analyze the used algorithms and data processing methods.
- Familiarize yourself with the mechanisms and methods of further transferring processed data to databases or other services for analysis and reporting, in particular in the context of storing and transmitting data in a format that meets security and efficiency standards.
- Ensure code uniqueness and reusability through the use of design patterns, functional programming, and other methods of structuring and optimizing code.
- Optimize the code for optimal performance and data processing speed.
- Conduct testing and validation of the finished solution in the environment and then using the Airflow orchestrator to meet the requirements and quality standards of the project.
Amazinum Data Engineers In Action
Our team of Data Engineers took on the task of optimizing existing code to address performance issues. We went through each code notebook in detail, identifying areas of duplication and inefficiencies. By applying optimization techniques and using cloud computing resources, we have successfully reduced the code size by more than 10 times, optimized the pipeline, and improved execution speed by more than 80%.
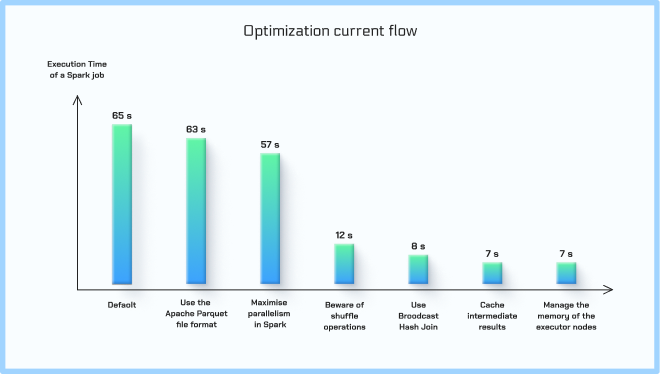
Using Google Cloud Platform services such as BigQuery for data processing and analysis, we optimized data loading processes to minimize delays and improve performance. Apache Zeppelin was the primary tool for the task at hand, serving as our collaborative data analytics tool, allowing interactive exploration and visualization of data transformations.
In addition, we used Apache Spark to parallelize data processing tasks, using its distributed computing capabilities to accelerate calculations. By tuning SQL queries and optimizing data processing operations, we have achieved significant improvements in processing speed and efficiency.
In general, a systematic approach to code optimization and the use of available tools and technologies led to a significant optimization of the data processing pipeline for the client, providing optimal performance and scalability even more than expected for the business needs.
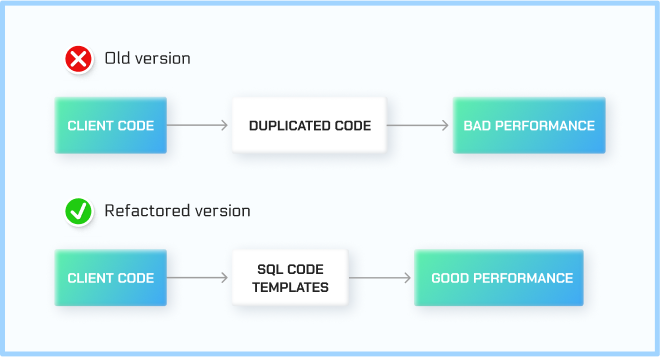
The result of Amazinum's work
Data Engineers optimized over 20 working laptops with code. The code was hosted in the cloud, which allowed us to use the client’s computing resources to test the degree of optimization we achieved.
Used Tools:
- Google Cloud Platform (GCP): Using GCP infrastructure and services to provide computing and storage capacity, as well as to integrate with other services.
- BigQuery: Using the high-performance BigQuery database for fast and scalable analysis of large volumes of data, optimizing queries and extracting the necessary information.
- Apache Airflow: Using a platform to manage workflows and data pipelines to automate, monitor, and schedule tasks.
- Apache Zeppelin: Using an interactive environment to execute code in programming languages like Scala, Python, SQL, etc., with data visualization and analytical report development.
- Apache Spark: Using a distributed framework to process large amounts of data in parallel and efficiently, using various modules for analytics, machine learning, and processing data streams.
- SQL: Using query language to manipulate and optimize data in databases, ensuring consistency and efficiency of processing.
- Pytest: Using a framework for automated testing of Python code, including testing data pipelines, Airflow tasks.
Outcome of Implementating Data Engineering
Data Integration
Data integration is the process of combining information from multiple sources, including online interactions, supply chain, sales transactions, and customer reviews, into a single data warehouse or data lake so that it can be analyzed.
Data Transformation and Cleaning
Putting raw data into a useable format and then filtering, cleaning, and other processes to ensure data quality. Managing outliers, inconsistent data, and missing values are all part of this process.
Data Modeling
Data modeling is the process of creating models of the relationships and patterns found in data so that companies can use the information to forecast and obtain new insights. Creating models for demand forecasting, customer segmentation, or recommendation systems are a few examples of this.
Data Pipelines
Establishing automated data pipelines to guarantee timely and effective data processing by streamlining the flow of data from source to destination.
Performance Optimization
Performance optimization is the process of improving data processing and storage to save costs and increase performance. A few examples of how to do this are by optimizing database queries or utilizing distributed computing frameworks like Apache Spark.
Real-time Data Processing
Personalized product recommendations based on browsing behavior are just a few examples of the instant insights and actions that can be enabled by implementing real-time data processing.
Data Governance and Security
Creating policies and processes to guarantee data privacy, quality, and compliance with laws like the CCPA and GDPR is known as data governance and security.
Business Intelligence and Reporting
Business intelligence and reporting: Giving stakeholders access to interactive dashboards and reports that illustrate important metrics and trends so they can decide with knowledge.
Review


Data Science & Analytics Services for Fashion House
They were good at thinking about solutions and had a high level of expertise in data science.
Thanks to Amazinum’s efforts, the client optimized and created a large number of Zeppelin notebooks. Moreover, the client appreciated the team’s good cooperation and clear communication throughout the project. Amazinum delivered on time and was outstandingly professional.

5.0
★ ★ ★ ★ ★
They were good at thinking about solutions and had a high level of expertise in data science.
